3.0 🚧 K-Means-Clusteranalyse
Synopsis: [datatab.de/tutorial/k-means-clusteranalyse 🔗] [databasecamp.de/ki/k-means-cluster 🔗]
Kann ein Datenanalyst aus den Trainingsdaten Cluster erkennen?
Gibt es eine “Cluster-Logik” hinter den Daten, die nutzbar ist?
- Die Trainings-Daten werden in einem n-dimensionalen Vektorraum angeordnet und sind nicht klassifiziert.
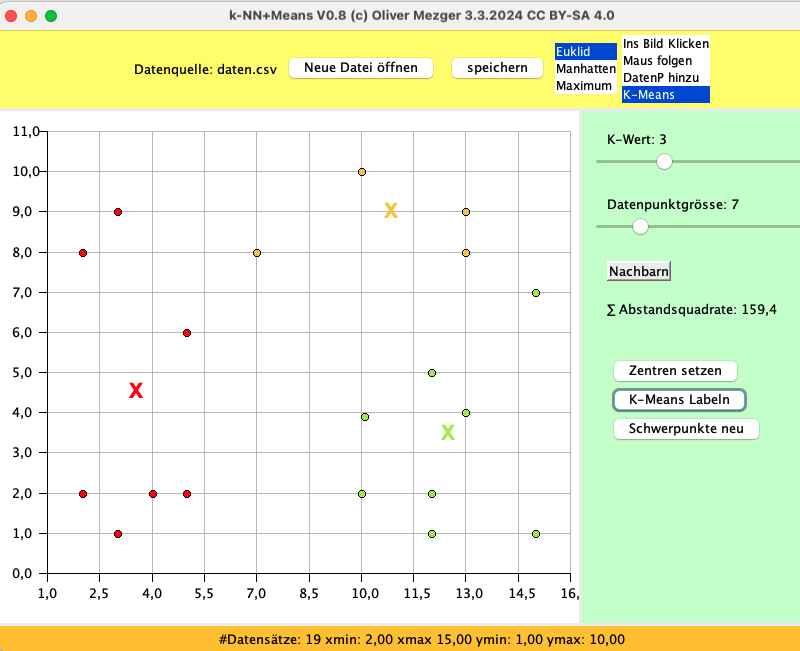
- Finde eine Anzahl von k-Cluster-Zentren um die Daten möglichst gut in k-Cluster einteilen zu können.
- Beginne mit z.B. k=3 und lege zufällig im Datenraum k Zentren mit unterschiedlichen Labeln fest.
- Bestimme für jeden Datenpunkt das nächste Zentrum (Metriken beachten) im Datenraum und gib ihm das Label des nächsten Zentrums.
- Ermittle dabei die Distanz des Datenpunkts zum gewählten Zentrum und addiere das Quadrat dieser Distanz in einer Variablen auf..
- Bestimme die Positionen der Zentren neu: Nimm alle Datenpunkte mit dem Label des jeweiligen Zentrums und ermittle dessen damit Schwerpunkt neu.
- Wiederhole mit 2. bis sich die Zentren nicht mehr verschieben.
- Erhöhe k und fang wieder bei 1. an.
- Wenn die Summe der Abstandsquadrate der Datenpunkte zum jeweiligen Zentrum nicht mehr deutlich abnimmt wurde ein k und die Zentren gefunden..